在关系型数据库中,事务隔离级别是保证数据一致性的关键机制。不同的隔离级别决定了事务之间如何相互影响,以及一个事务对另一个事务的可见性。本文将以PostgreSQL源码为切入点,深入分析关系型数据库隔离级别的具体实现原理,并通过SQL示例演示不同隔离级别的行为差异。
一、数据库隔离级别概述
ACID特性与隔离级别的关系
数据库事务的ACID特性包括:
- 原子性(Atomicity):事务作为一个整体执行,要么全部成功,要么全部失败
- 一致性(Consistency):事务执行前后,数据库保持一致状态
- 隔离性(Isolation):事务之间相互隔离,互不干扰
- 持久性(Durability):事务提交后,数据永久保存
隔离级别正是用来定义事务之间隔离程度的标准,它决定了一个事务对另一个事务的可见性。
四种标准隔离级别
SQL标准定义了四种隔离级别:
- 未提交读(Read Uncommitted):可能读取到未提交的数据(脏读)
- 已提交读(Read Committed):只能读取已提交的数据
- 可重复读(Repeatable Read):在一个事务中多次读取相同数据结果一致
- 序列化(Serializable):最高隔离级别,事务按顺序执行
PostgreSQL实现了其中三种隔离级别,不支持未提交读(Read Uncommitted)。
二、PostgreSQL隔离级别实现原理
1. 读已提交(Read Committed)隔离级别实现
读已提交是PostgreSQL的默认隔离级别,它保证事务只能读取已提交的数据,但在同一个事务中多次查询可能得到不同结果(不可重复读)。
实现原理
PostgreSQL使用MVCC(Multi-Version Concurrency Control)机制实现读已提交隔离级别:
- 每次查询开始时生成一个新的快照,因此同一事务中不同查询可能看到不同数据
SQL演示
-- 创建测试表
CREATE TABLE test_table (id INT, value TEXT);
INSERT INTO test_table VALUES (1, 'initial');
-- 会话1(开启读已提交事务)
BEGIN TRANSACTION ISOLATION LEVEL READ COMMITTED;
SELECT value FROM test_table WHERE id = 1; -- 输出: initial
-- 会话2(另一个事务)
BEGIN TRANSACTION;
UPDATE test_table SET value = 'updated' WHERE id = 1;
-- 会话1此时查询仍看到initial,因为会话2未提交
-- 会话2提交事务
COMMIT;
-- 会话1再次查询
SELECT value FROM test_table WHERE id = 1; -- 输出: updated
COMMIT;
源码追踪
查看test_table 数据的xmin事务号
[postgres@edc-pdf-dmdb02 ~]$ psql test
psql (17beta1)
Type "help" for help.
test=# select xmin ,* from test_table ;
xmin | id | value
------+----+---------
782 | 1 | initial
(1 row)
- 执行查询
test=# BEGIN TRANSACTION ISOLATION LEVEL READ COMMITTED;
BEGIN
test=*# SELECT value FROM test_table WHERE id = 1; -- 输出: initial
-
获取snapshot
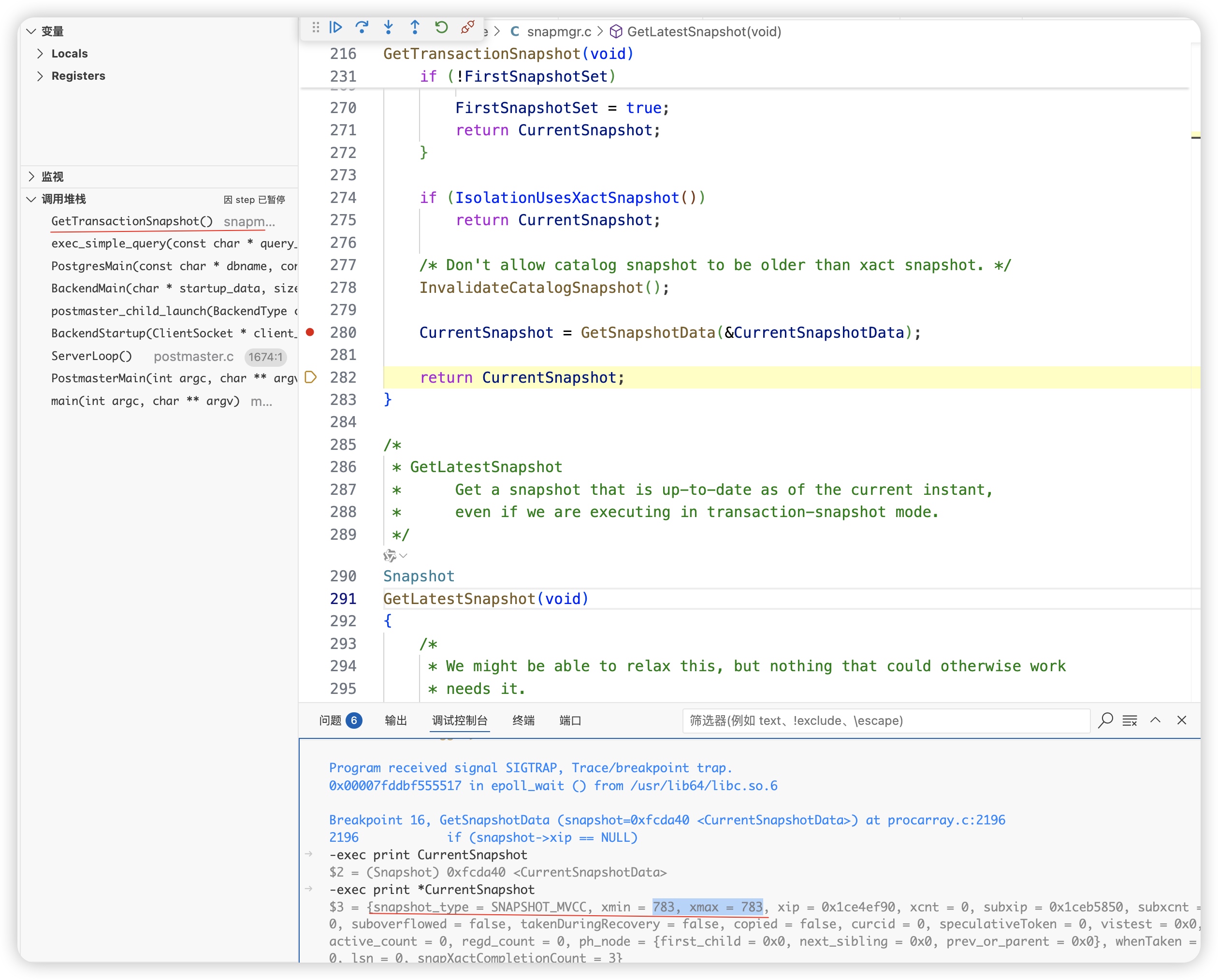
-
判断数据是否对该snapshot可见
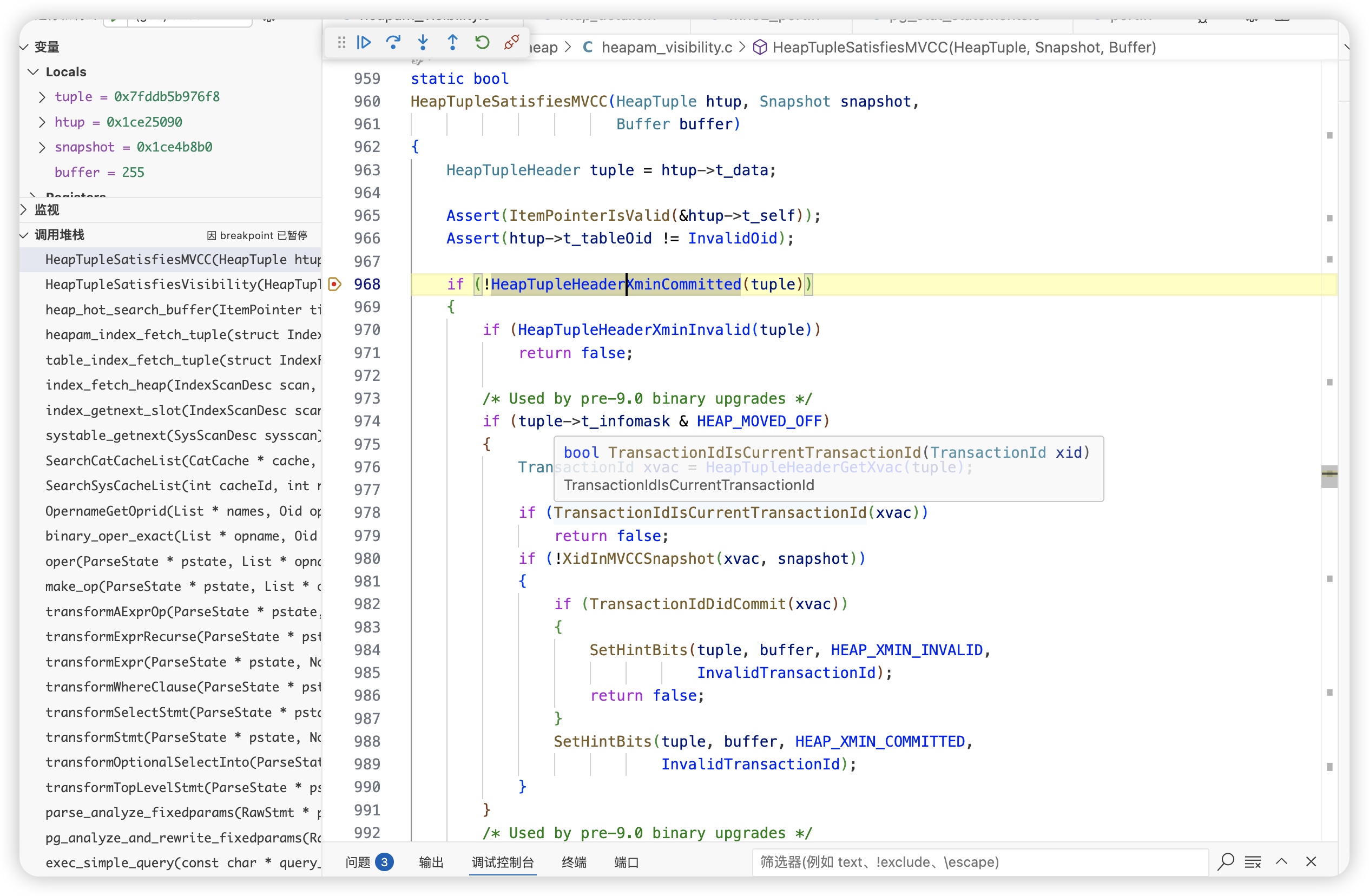
- 会话2 执行另一个事务并提交 此时xmin值已经增加了一个事务号
test=# BEGIN TRANSACTION;
UPDATE test_table SET value = 'updated' WHERE id = 1;
BEGIN
UPDATE 1
test=*# COMMIT;
COMMIT
test=# select xmin,xmax,id,value from test_table where id =1;
xmin | xmax | id | value
------+------+----+---------
783 | 0 | 1 | updated
(1 row)
test=#
- 会话1 重新执行查询
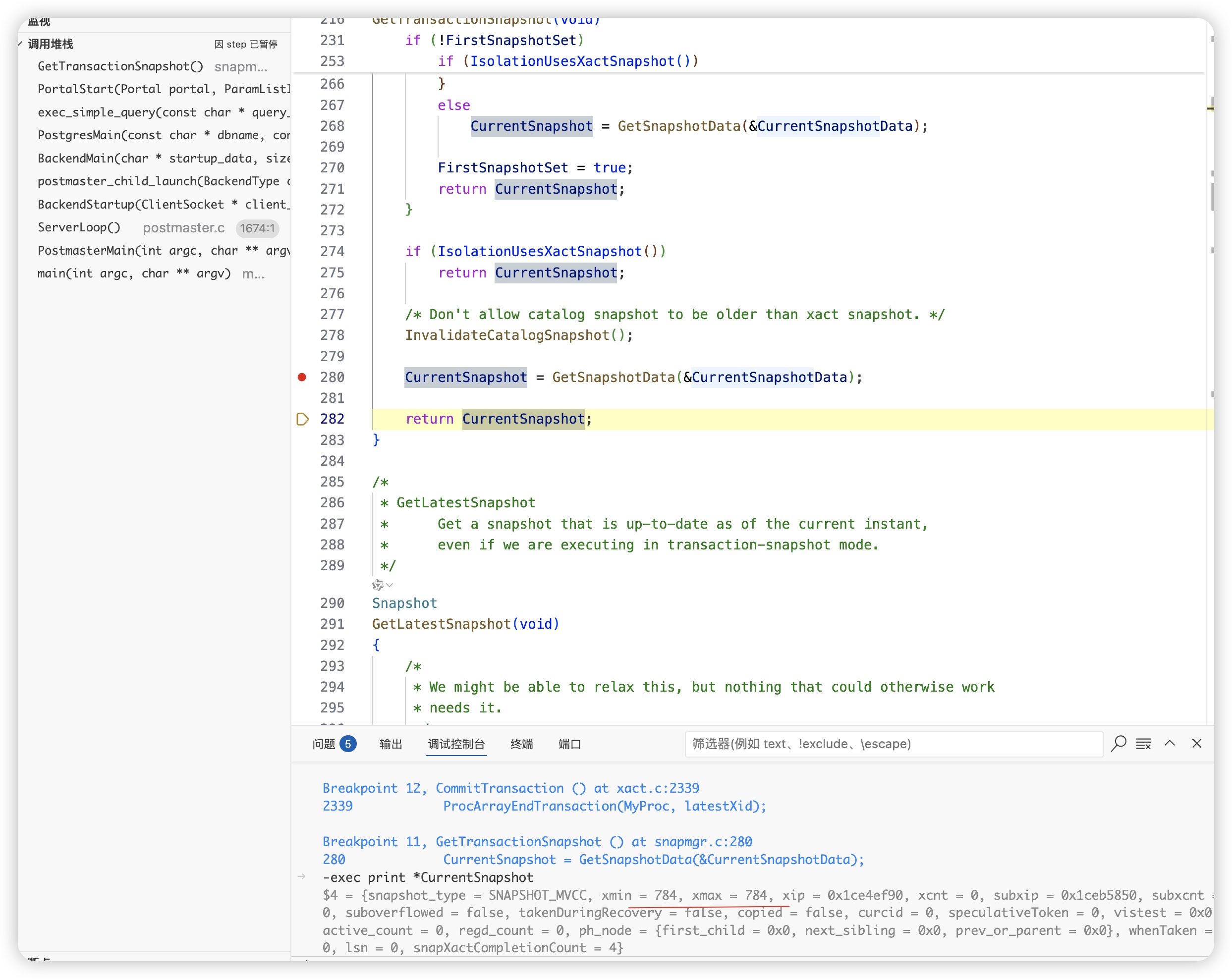
读已提交(Read Committed),每次查询会重新申请一个snapshot,所以可以看到最新提交的数据。
test=# SELECT value FROM test_table WHERE id = 1;
value
---------
updated
(1 row)
2. 可重复读(Repeatable Read)隔离级别实现
可重复读隔离级别保证在同一个事务中多次查询相同数据时结果一致,避免不可重复读和幻读(部分实现)。
实现原理
PostgreSQL的可重复读实现基于:
- 事务开始时生成一个固定的快照,整个事务期间使用该快照
- 快照包含所有已提交事务ID和当前活跃事务ID
- 读取时只访问创建事务ID在快照之前或已提交,且不在活跃事务中的版本
SQL演示
-- 会话1(开启可重复读事务)
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SELECT * FROM test_table; -- 当前为1条记录
-- 会话2(另一个事务)
BEGIN TRANSACTION;
INSERT INTO test_table VALUES (2, 'new');
COMMIT;
-- 会话1再次查询
SELECT * FROM test_table; -- 仍返回1,看不到会话2的插入
COMMIT;
-- 提交后查询
SELECT * FROM test_table; -- 现在返回2
源码追踪
会话一: 设置隔离级别 BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
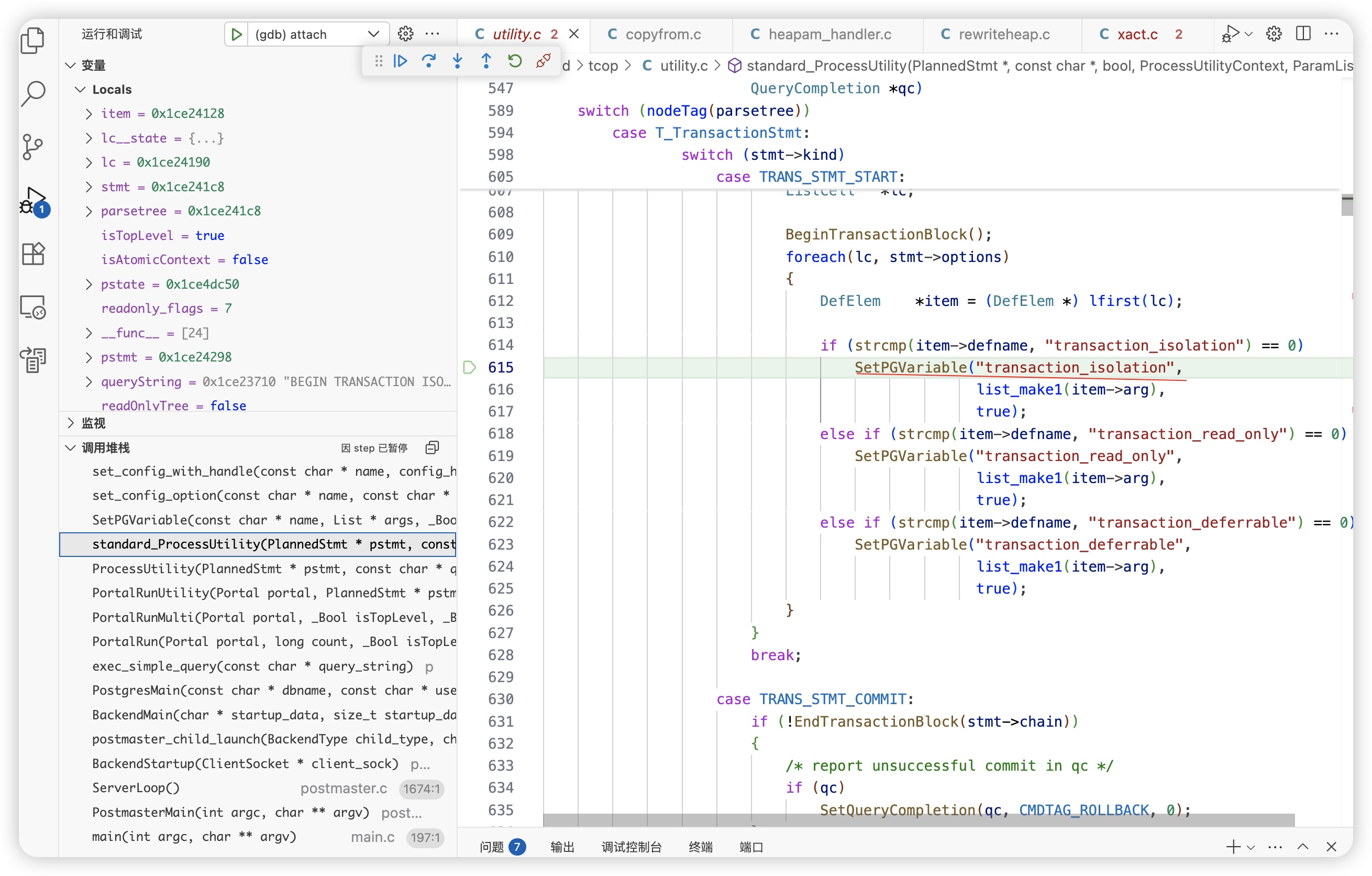
第一次查询: SELECT * FROM test_table;
获取snapshot
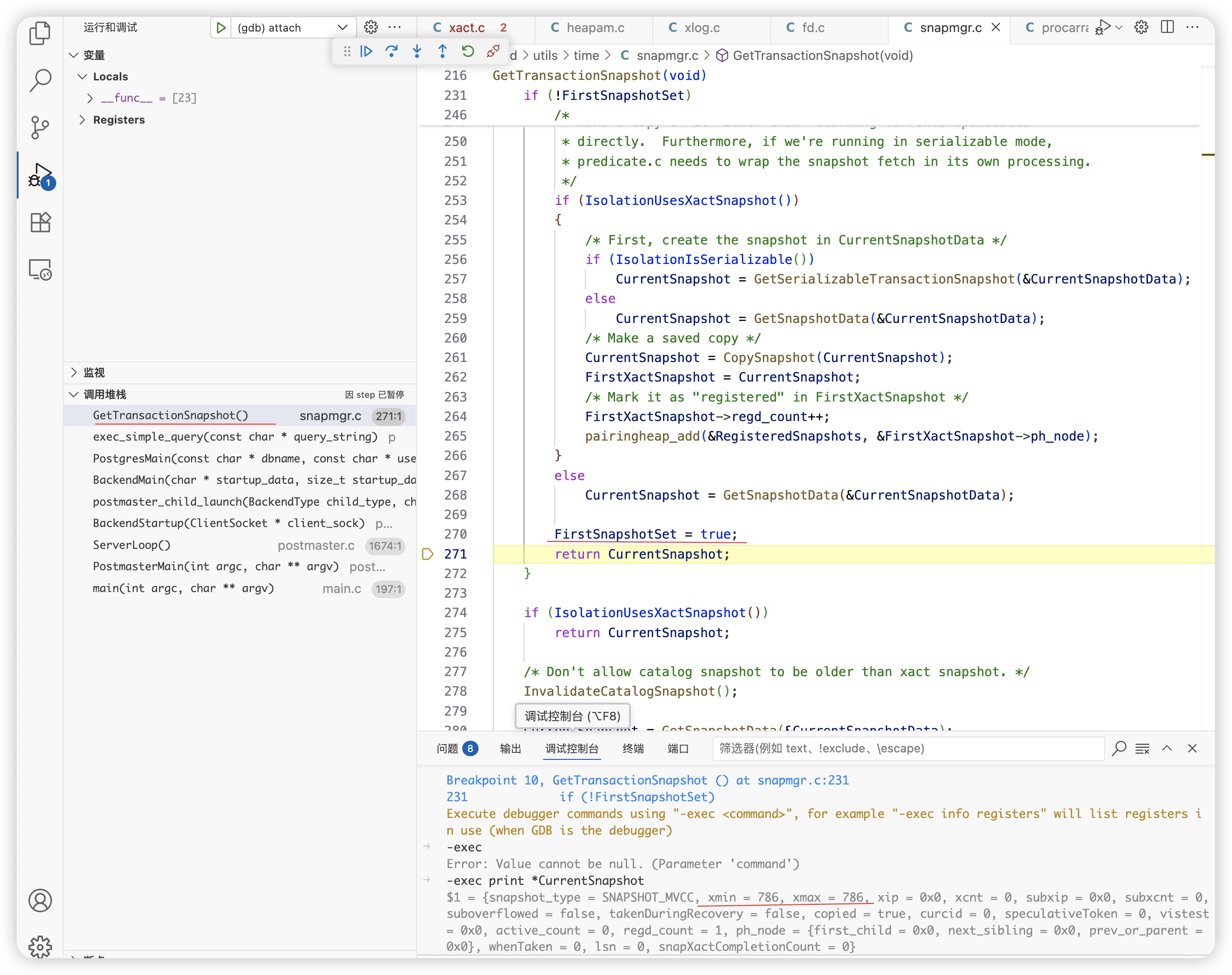
会话二:
test=# BEGIN TRANSACTION;
INSERT INTO test_table VALUES (2, 'new');
COMMIT;
BEGIN
INSERT 0 1
COMMIT
test=# select * from test_table ;
id | value
----+---------
1 | updated
2 | new
(2 rows)
test=#
会话一 重新查询:
第二次查询时,会根据当前的隔离级别是否需要重新申请snapshot,当隔离级别XactIsoLevel >= XACT_REPEATABLE_READ(隔离级别是XACT_REPEATABLE_READ或XACT_SERIALIZABLE),不需要重新申请snapshot,一个事务只用一个snapshot。这样就实现了新插入的数据在REPEATABLE_READ情况下查询不到的效果。
#define IsolationUsesXactSnapshot() (XactIsoLevel >= XACT_REPEATABLE_READ)
#define XACT_READ_UNCOMMITTED 0
#define XACT_READ_COMMITTED 1
#define XACT_REPEATABLE_READ 2
#define XACT_SERIALIZABLE 3
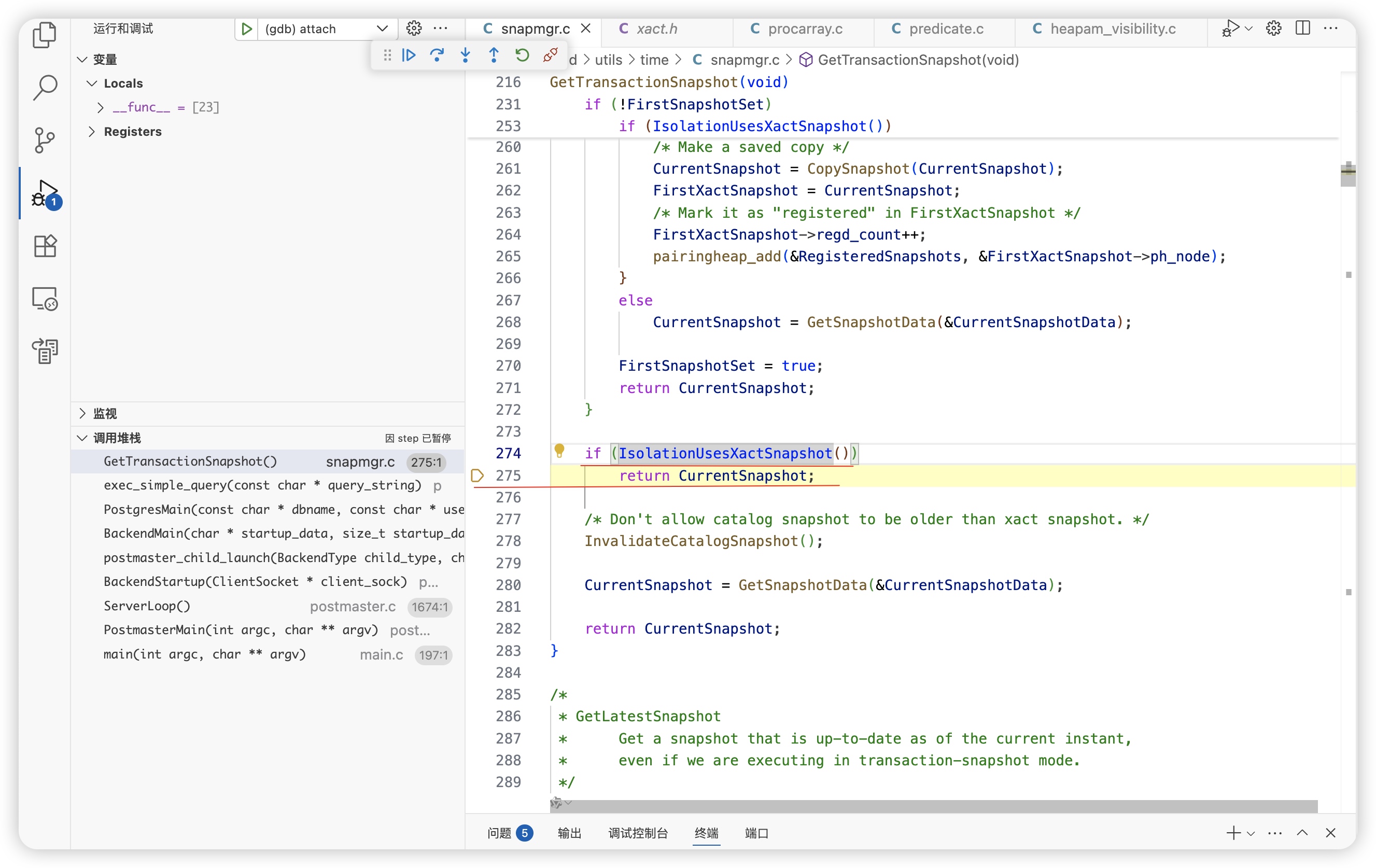
test=# BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
BEGIN
test=*# SELECT * FROM test_table;
id | value
----+---------
1 | updated
(1 row)
test=*# SELECT * FROM test_table;
id | value
----+---------
1 | updated
(1 row)
test=*#
3. 序列化(Serializable)隔离级别实现
序列化是最高隔离级别,它保证事务的执行效果与串行执行相同,完全避免并发问题。
实现原理
PostgreSQL的序列化实现基于:
- 扩展的MVCC机制,结合SSI(Serializable Snapshot Isolation)
- 事务执行时跟踪所有读取和写入的资源
- 检测可能导致序列化异常的并发事务
- 发现冲突时,终止其中一个事务(通常是较新的事务)
SQL演示
-- 会话1(开启序列化事务)
BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE;
SELECT balance FROM accounts WHERE id = 1;
-- 会话2(另一个序列化事务)
BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE;
UPDATE accounts SET balance = balance + 500 WHERE id = 1;
COMMIT; -- 成功提交
-- 会话1尝试更新
UPDATE accounts SET balance = balance - 500 WHERE id = 1;
COMMIT; -- 可能抛出序列化失败异常:
-- ERROR: could not serialize access due to concurrent update
源码追踪
会话1 (开启序列化事务)
- 设置隔离级别并查询
test=# BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN
test=*# SELECT balance FROM accounts WHERE id = 1;
balance
---------
1000.00
(1 row)
- 获取snapshot
序列化隔离级别使用特殊的GetSerializableTransactionSnapshot 函数获取快照。GetSerializableTransactionSnapshot 是为 SERIALIZABLE 隔离级别设计的,具有更强的一致性保证,但性能开销较大;而 GetSnapshotData 更轻量,适用于大多数常规事务场景
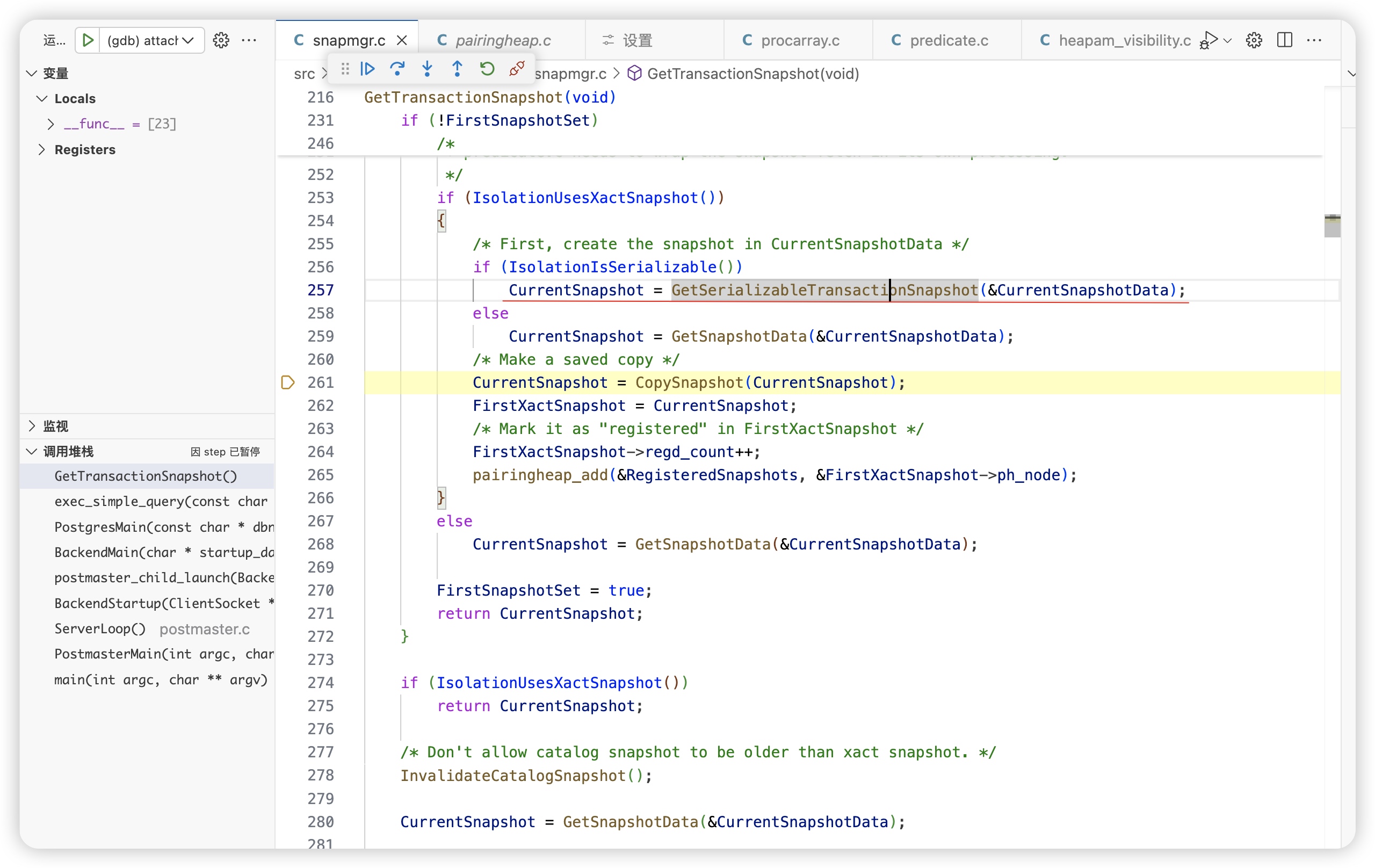
- 添加谓词锁
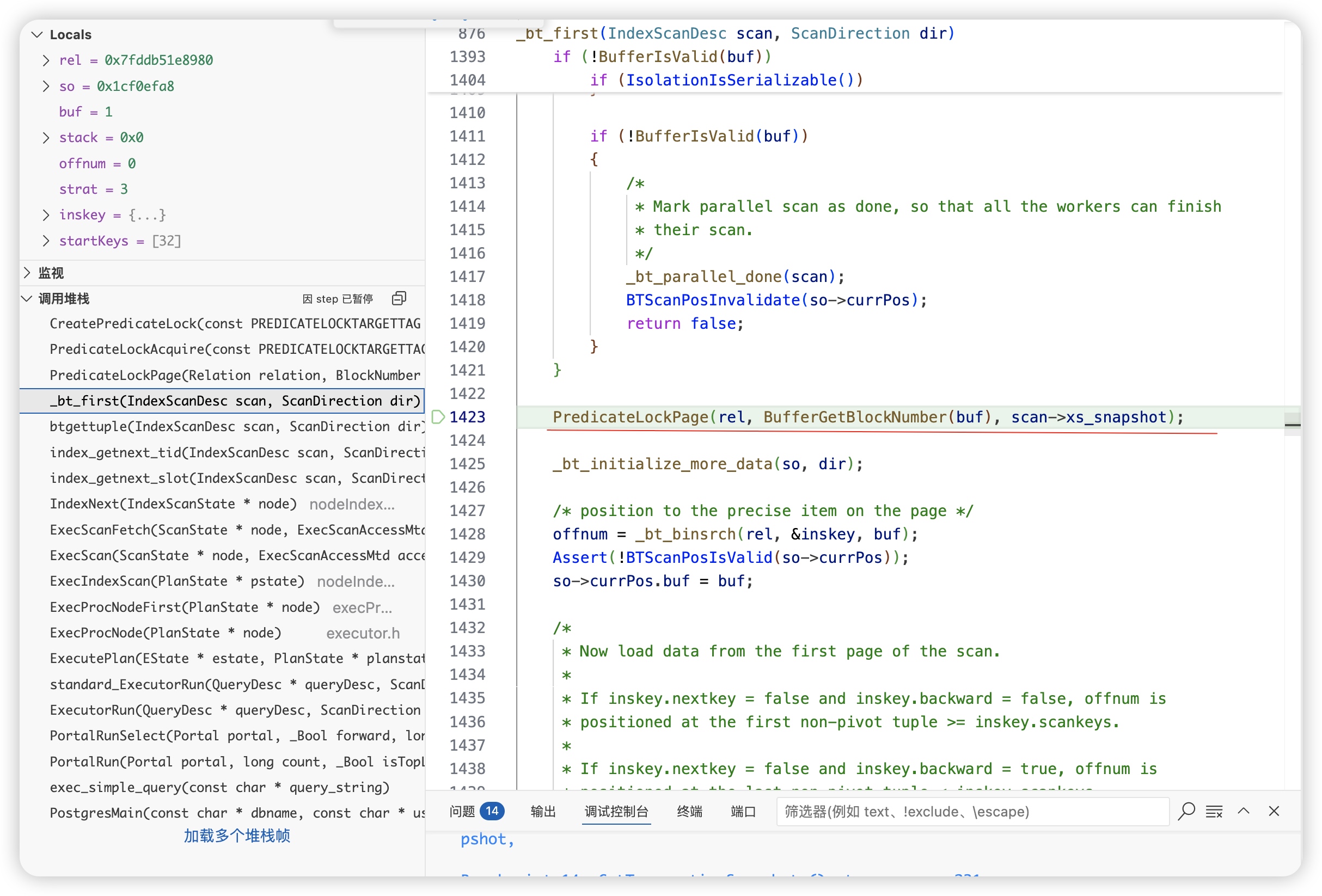
会话2(另一个序列化事务)
test=# BEGIN TRANSACTION ISOLATION LEVEL SERIALIZABLE;
UPDATE accounts SET balance = balance + 500 WHERE id = 1;
COMMIT; -- 成功提交
BEGIN
UPDATE 1
COMMIT
会话1尝试更新
test=*# UPDATE accounts SET balance = balance - 500 WHERE id = 1;
-
根据隔离级别判断需要检测序列号冲突
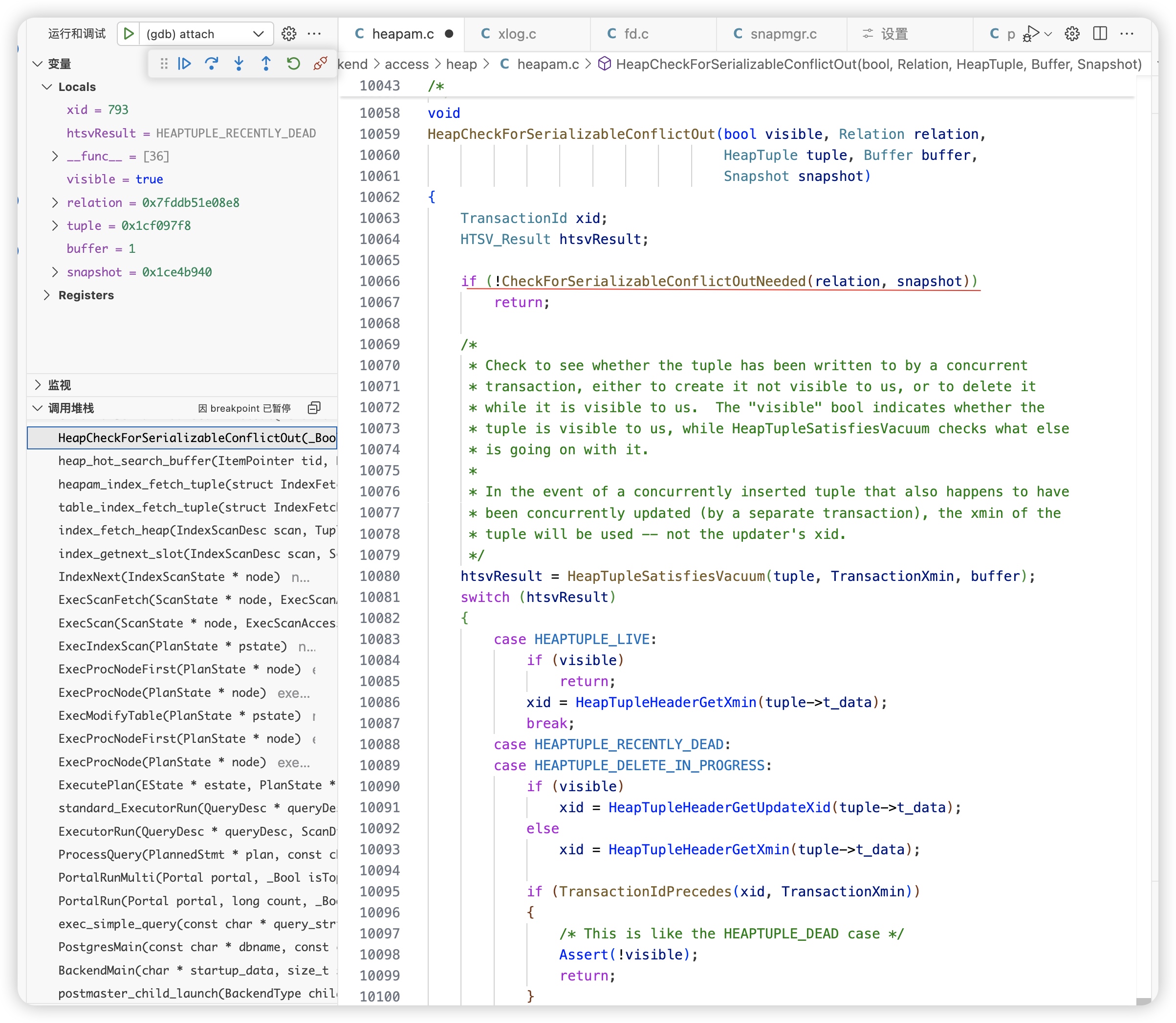
-
对于snapshot可见的数据加上谓词锁
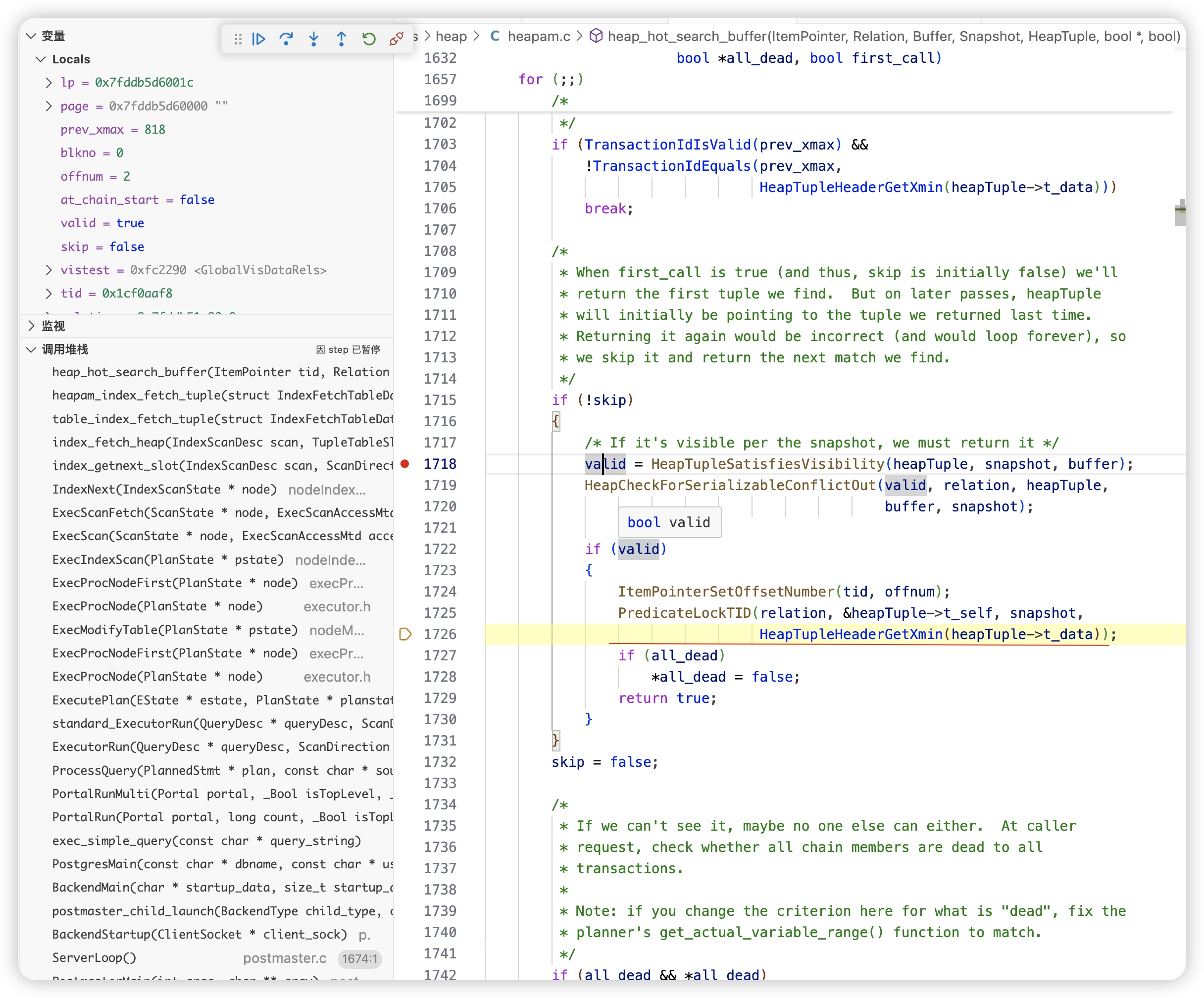
序列化隔离级别判断是否违反隔离级别的核心逻辑
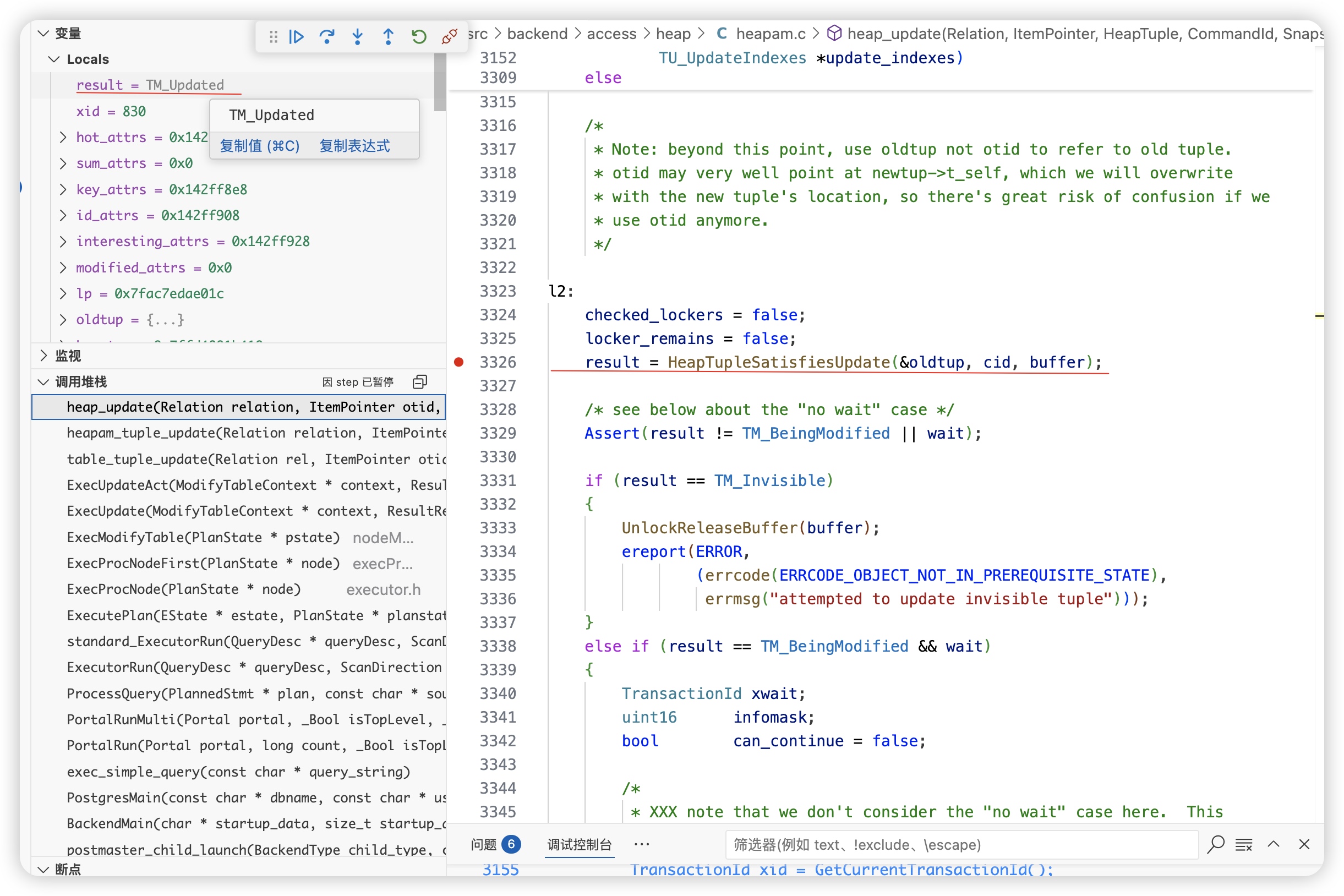
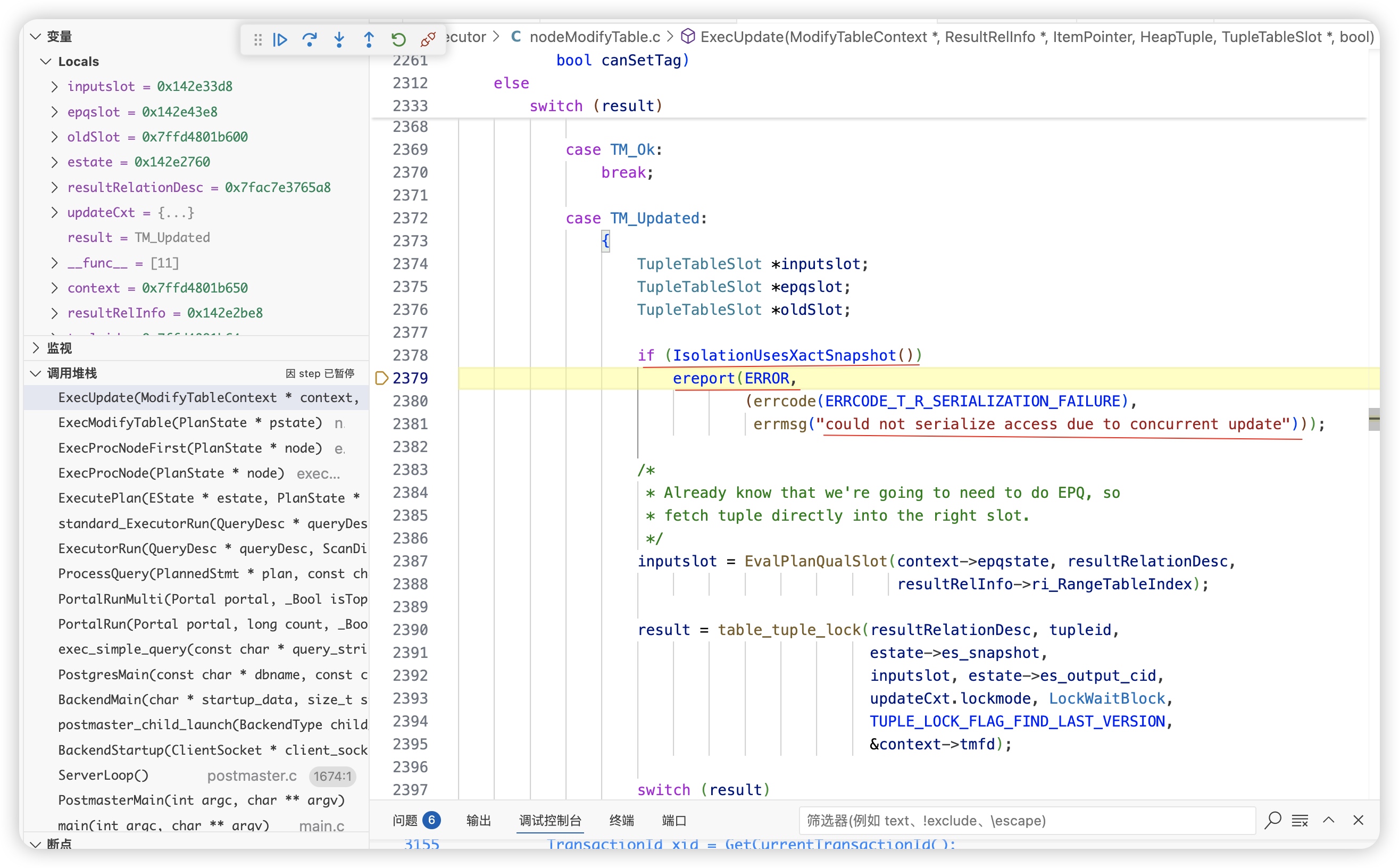
在heap_update 函数中,通过HeapTupleSatisfiesUpdate检测到该数据已经被其他事务修改了,result=TM_Updated,正常update成功的话,result=TM_Ok
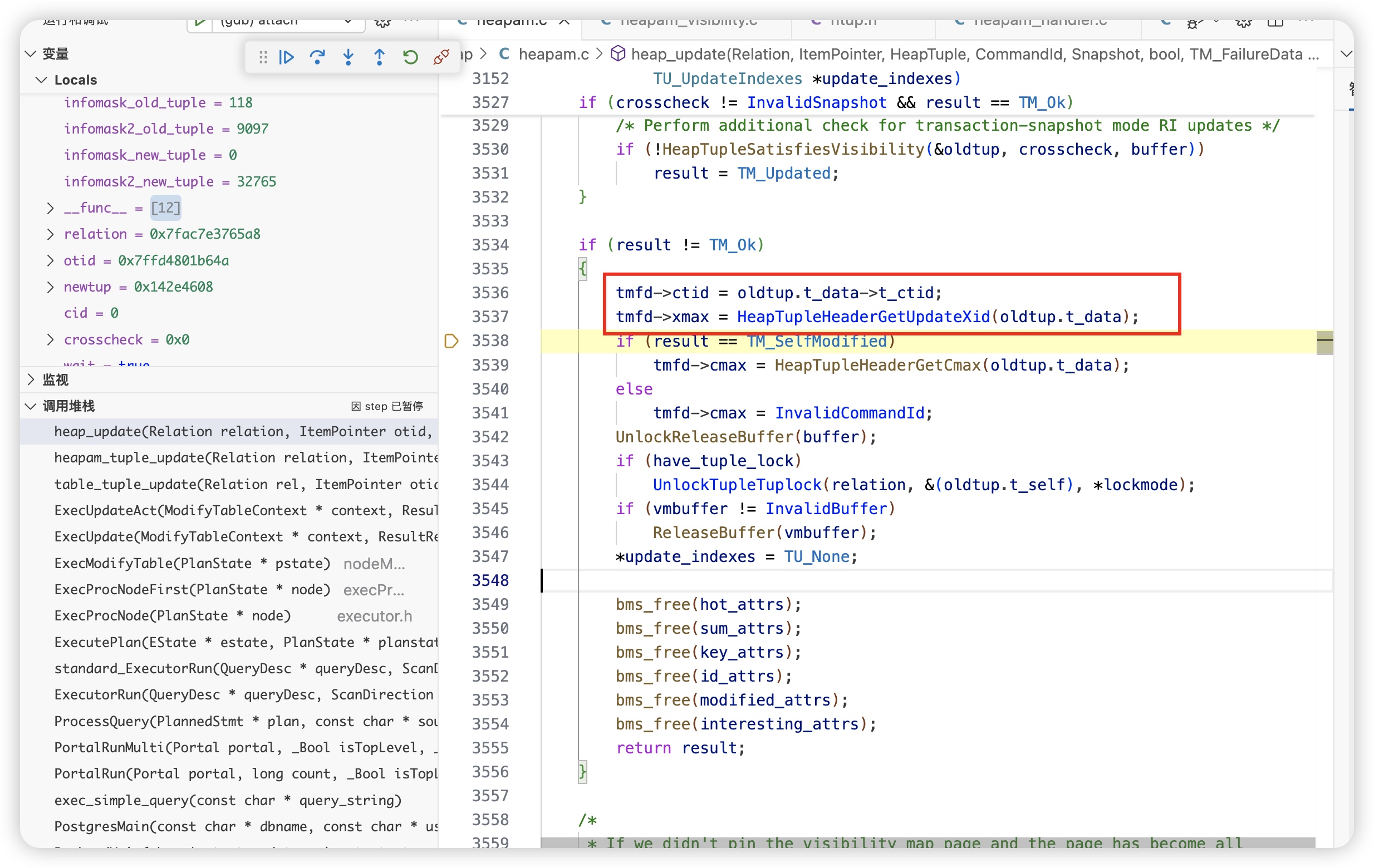
- 填充失败信息
tmfd->ctid: 设置为旧元组的 t_ctid,指向新版本元组的位置。 tmfd->xmax: 获取导致冲突的事务 ID(通常是正在修改该元组的另一个事务)。
- ExecUpdate 函数中根据子调用里返回的result为TM_Updated,判断不符合序列化隔离级别,抛出错误,完成序列化隔离级别的功能。
三、不同隔离级别性能与一致性权衡
隔离级别与性能关系
| 隔离级别 | 一致性保障 | 并发性能 |
|---|---|---|
| 读已提交 | 避免脏读 | 最高 |
| 可重复读 | 避免脏读、不可重复读 | 中等 |
| 序列化 | 完全一致性 | 最低 |
PostgreSQL的实现特点
-
默认隔离级别选择:PostgreSQL选择读已提交作为默认隔离级别,在一致性和性能之间取得平衡
-
SSI机制:序列化隔离级别通过SSI机制实现,相比传统两阶段锁(2PL)有更好的并发性能
-
MVCC优势:所有隔离级别都基于MVCC实现,读操作不阻塞写操作,写操作不阻塞读操作
-
幻读处理:可重复读级别通过谓词锁部分解决幻读问题,序列化级别完全解决幻读
四、总结与实践建议
通过分析PostgreSQL源码,我们可以看到关系型数据库隔离级别的实现本质上是对事务可见性的精确控制。MVCC机制是实现高并发隔离的核心,而不同隔离级别则是在可见性规则上的差异。
在实际应用中:
- 对于大多数业务场景,读已提交(Read Committed)是最佳选择,既能保证基本一致性,又有良好性能
- 对于需要多次读取相同数据的场景,可考虑使用可重复读(Repeatable Read)
- 序列化(Serializable)隔离级别仅建议在对一致性要求极高且并发冲突较少的场景使用
理解隔离级别的实现原理,有助于我们在开发和运维中更好地选择和使用合适的隔离级别,平衡数据一致性和系统性能。