测试环境和数据
test=# \d t1
Table "public.t1"
Column | Type | Collation | Nullable | Default
--------+------------------------+-----------+----------+---------
id | integer | | |
name | character varying(100) | | |
Indexes:
"idx_t1" btree (id)
test=# select * from t1;
id | name
----+-------
1 | test1
(1 row)
test=# update t1 set name='test2' where id=1;
UPDATE 执行过程
- 读取旧值:首先读取要更新的行的当前值,这个值可能来自磁盘上的表或者数据库缓存。
- 计算新值:根据UPDATE语句中的表达式计算出新的值。
- 更新行:将新值写入到行中,如果是热更新,可能会通过修改行指针等方式进行优化更新;如果不是热更新,可能会创建一个新的行版本并插入到表中,同时更新相关的索引。
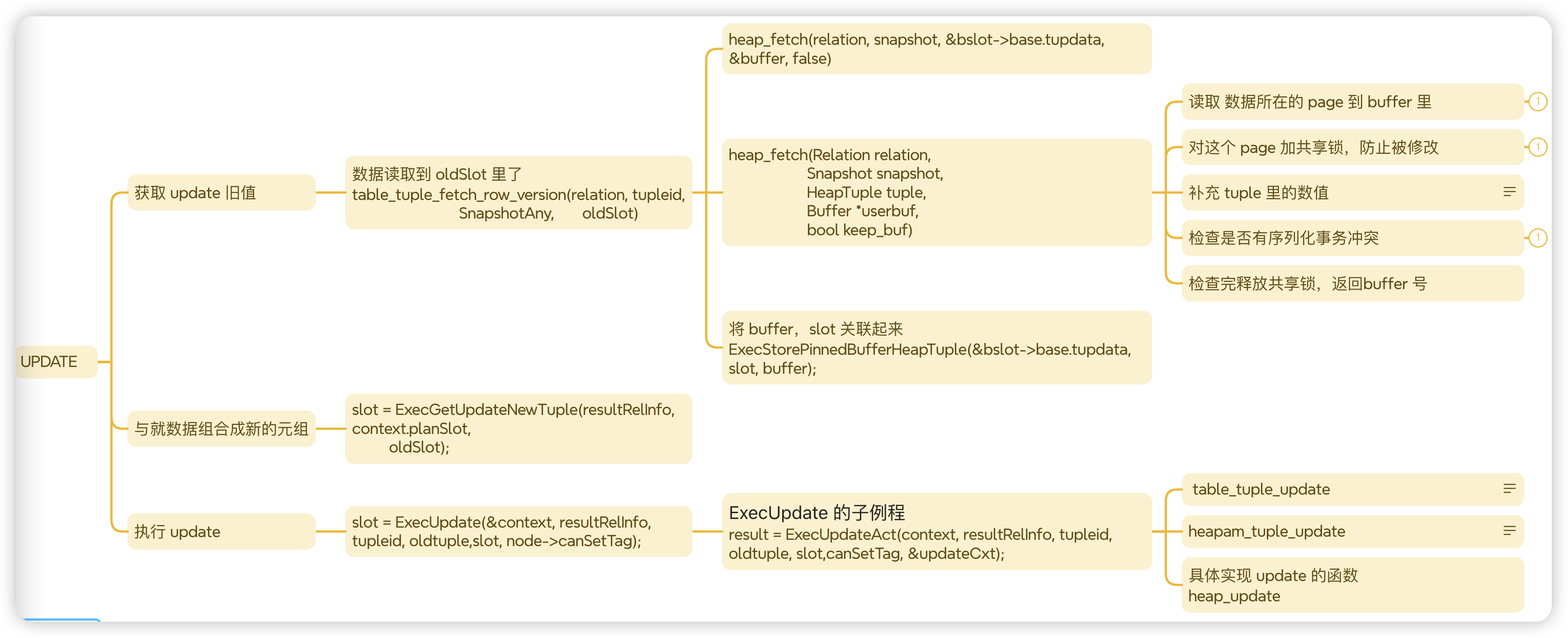
update的核心逻辑存在于heap_update函数之中。在该函数的注释里有说明(replace a tuple),其作用是替换一个元组。也就是说,postgresql update是一种替换操作,新的元组替换旧的元组。
heap_update 详细操作
update 前期操作

准备新值
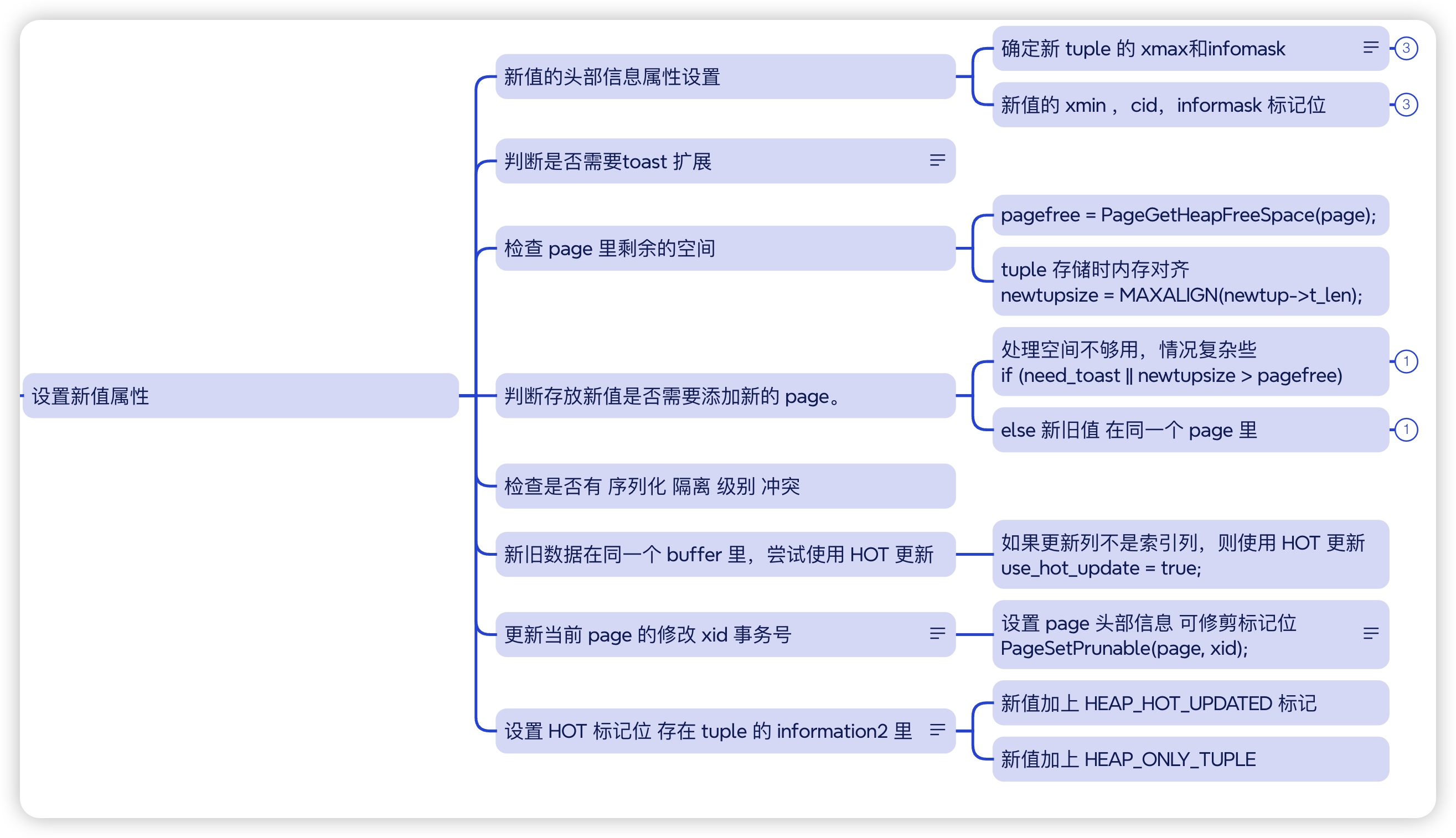
新值的informask 标记会添加HEAP_UPDATED 标记,表示是update 操作
newtup->t_data->t_infomask |= HEAP_UPDATED | infomask_new
使用 HOT 技术实现 update
在 PostgreSQL 中,HOT(Heap-Only Tuples,仅堆元组)是一种用于提高数据库性能的技术。 仅堆元组(Heap Only Tuple,HOT)特性消除了冗余的索引条目,并允许在不执行全表清理的情况下重新使用已删除或已过时的已更新元组所占用的空间。它通过允许单页清理来实现这一点,这种清理也被称为 “碎片整理” 或 “修剪”(详细参考backend/access/heap/README.HOT)
如果新旧数据存放在一个 page 里, 且更新的数值不含索引列,则可以使用 HOT 技术。
观察旧值
当前测试表是新建的表且只有一行数据,update 过程中此数据行所在的 page 页会读入 buffer 里,我们来验证一下,当前 page 里有多少个数据行。 heap_update 函数下面代码部分,是读入旧值到 buffer 里。
buffer = ReadBuffer(relation, block);
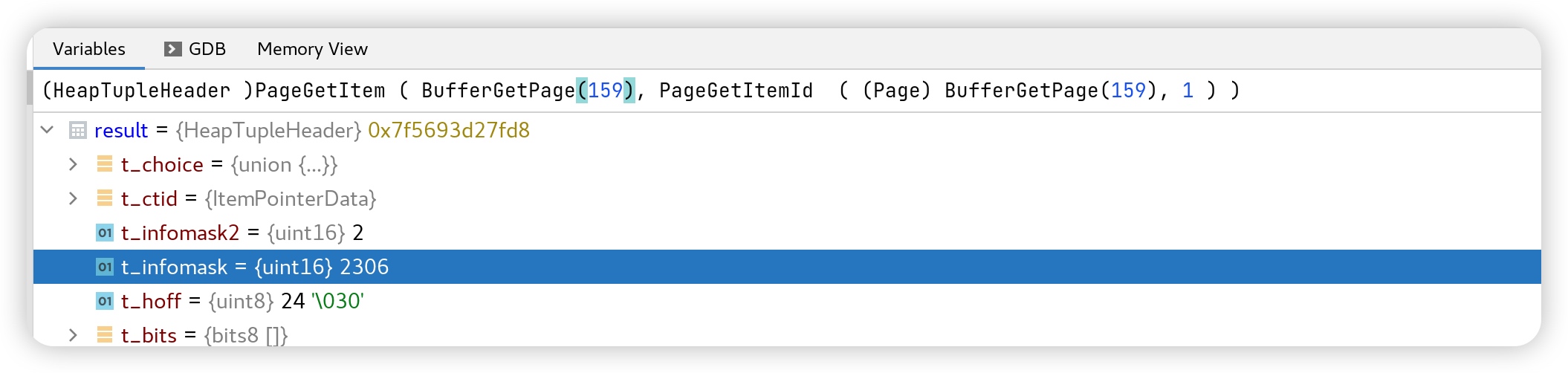
 debug 时看到,此数据被读入到159号 buffer page 里了。
查看这个 page里目前有多少个数据行,能看出只有 1 行数据,和测试数据吻合。
debug 时看到,此数据被读入到159号 buffer page 里了。
查看这个 page里目前有多少个数据行,能看出只有 1 行数据,和测试数据吻合。
 看看这行数据的属性,t_infomask 值为 2306。是几个16进制的的标记符组合而成的。(HEAP_XMAX_INVALID+HEAP_XMIN_COMMITTED+HEAP_HASVARWIDTH)
看看这行数据的属性,t_infomask 值为 2306。是几个16进制的的标记符组合而成的。(HEAP_XMAX_INVALID+HEAP_XMIN_COMMITTED+HEAP_HASVARWIDTH)
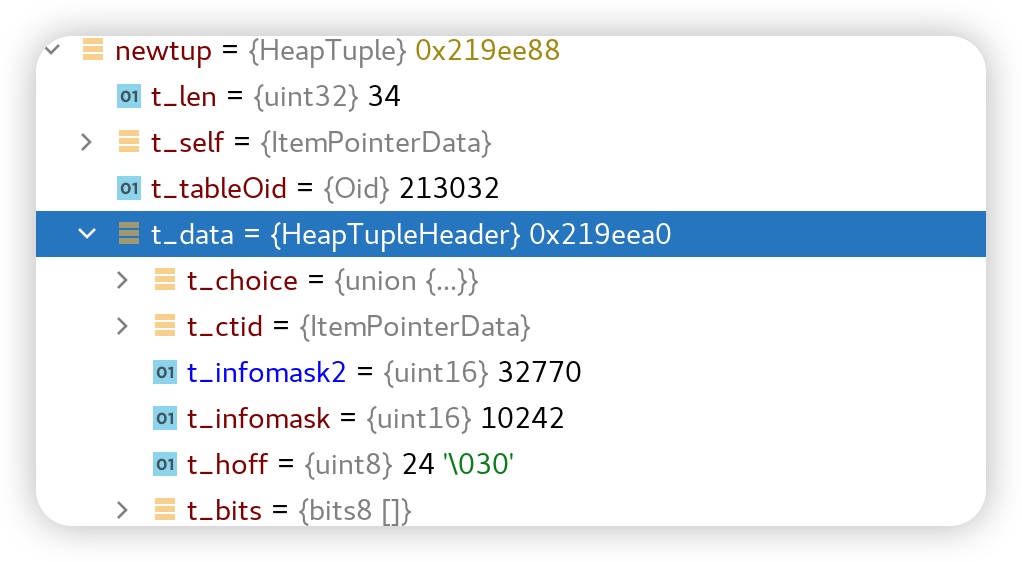
观察新值
新值的infomask是HEAP_XMAX_INVALID+HEAP_UPDATED+HEAP_HASVARWIDTH,infomask2 里是2+0X8000(HEAP_ONLY_TUPLE),说明新值是通过 HOT 更新过来的,此时旧值Infomask2 会加上
HEAP_HOT_UPDATED 标记,表示已经被HOT更新过了。
存入新值到buffer page 里

主要操作就是使用内存复制写入新值到指定内存位置
memcpy((char *) page + upper, item, siz e);
设置旧值的属性
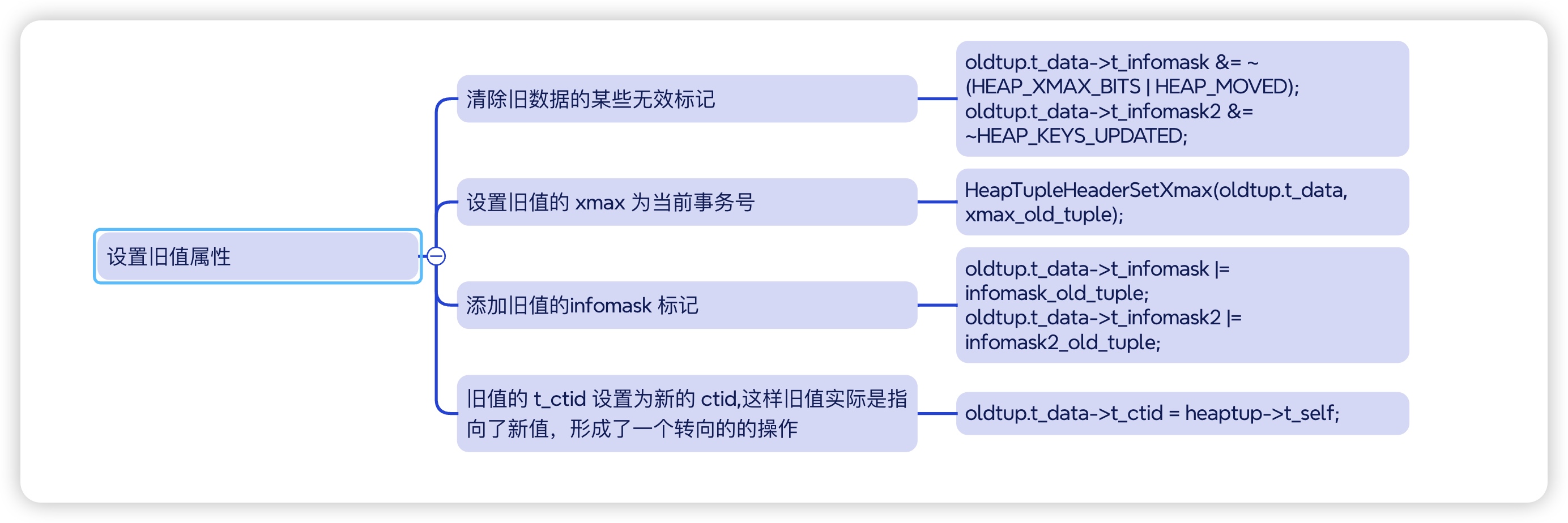
其中比较重要的是
- 设置xmax,这里面存储了该值update操作的事务号。
- 设置旧值的ctid指向新值的ctid,这样旧值虽然没有被清除,但查询时还是会指向新值。
heap update 操作后续操作
-
标记buffer 为脏页 ,checkpoint 时会写入到磁盘存储
-
写入wal 日志
-
解锁写入数据的buffer 在buffer上有锁的这段时间,任何对这个buffer 上数据的操作都会阻塞。包括 select 查询数据,因为查询会对该 buffer 加上共享锁,与存在的排他锁冲突

-
操作结束,返回update操作结果